PDF table extractor
Extract PDF tables into editable Excel files
Use a structure-aware PDF table extractor for reports, statements, invoices, and operational tables that need editable rows and columns.

Built for private business documents
- Async conversion keeps large PDF processing out of the browser request.
- Source PDFs and Excel outputs are cleaned up automatically by retention jobs.
- The public page shows simple review guidance; detailed telemetry stays internal.
Real extraction previews
Corpus-backed PDF to Excel examples
These visuals use synthetic regression PDFs and the actual Excel outputs produced by the TryPDF extraction engine.
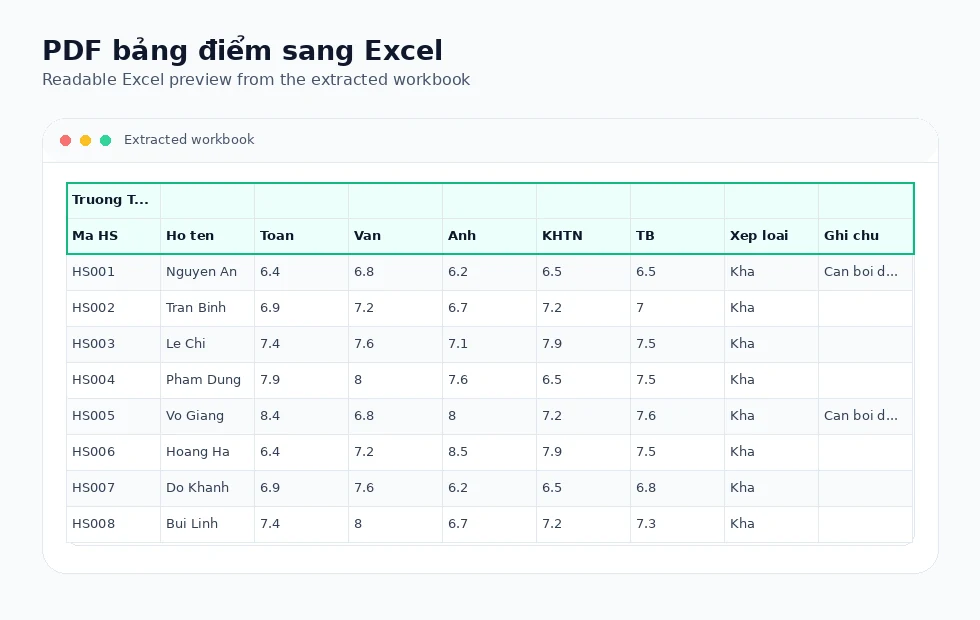
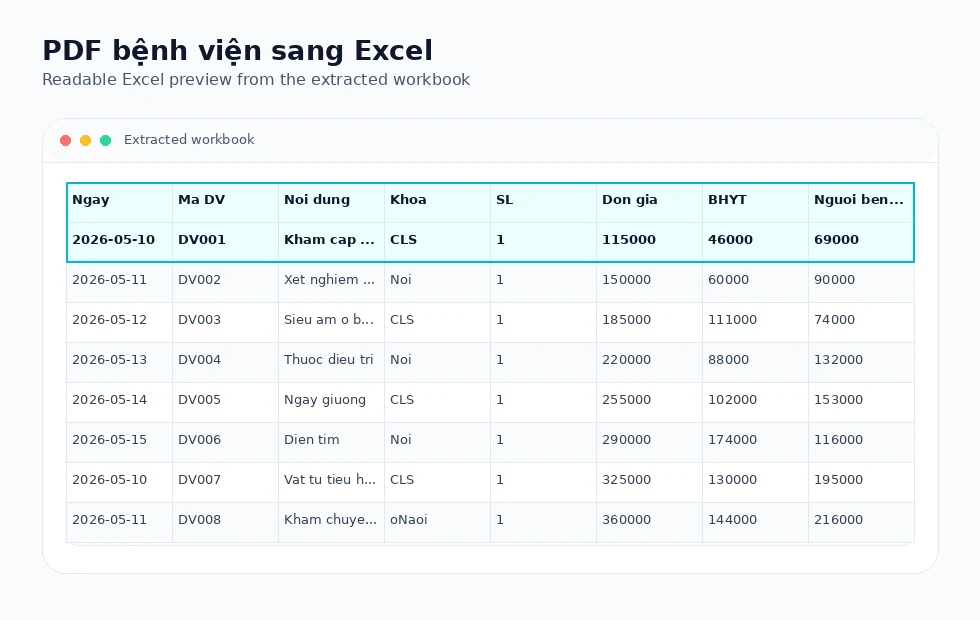
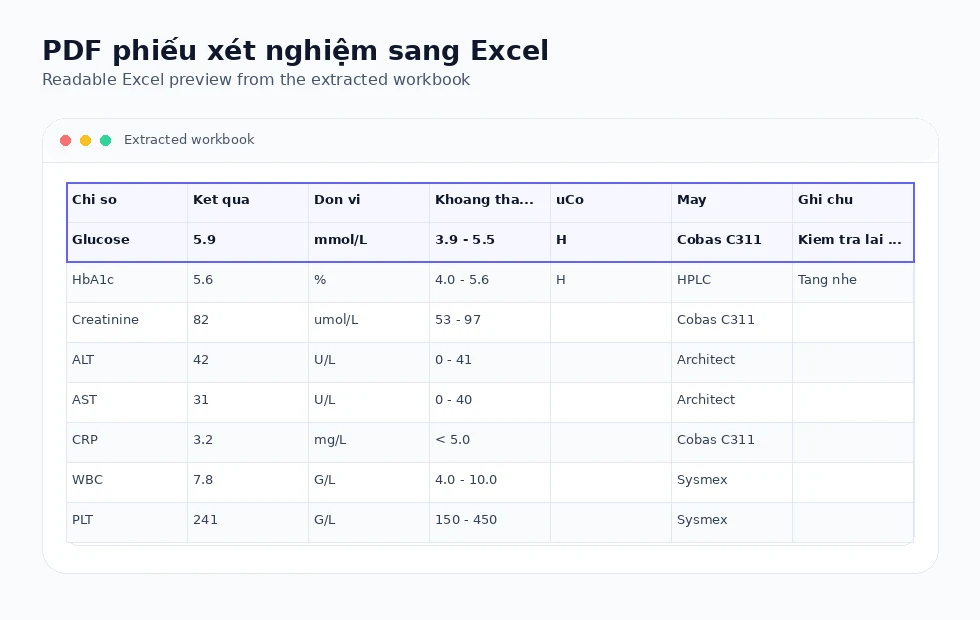
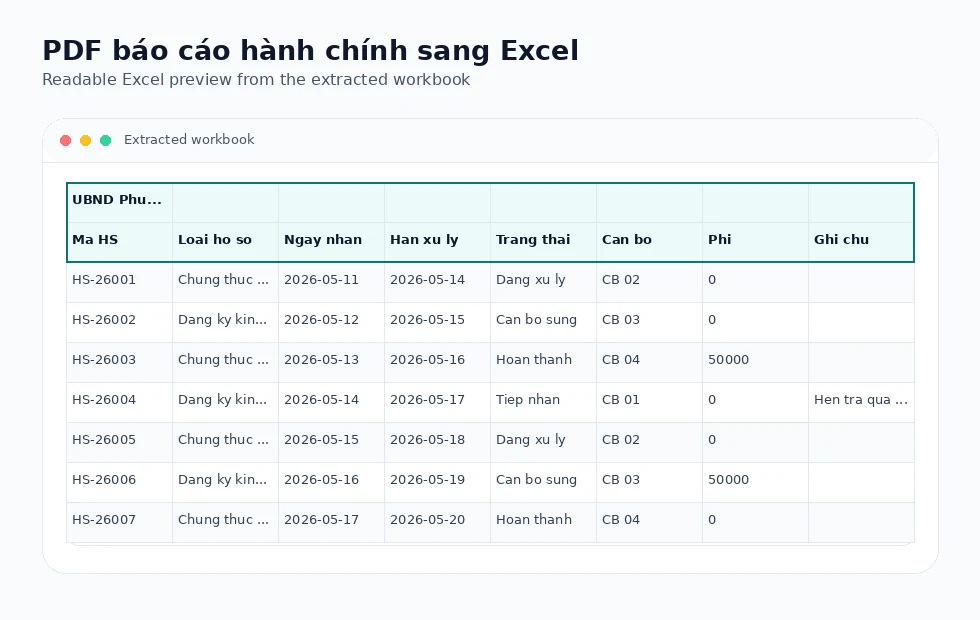
Real Excel output
Tables are written to .xlsx workbooks rather than copied as screenshots or plain text.
Bordered and borderless tables
The engine uses PDF table geometry first, then a conservative alignment fallback for clear borderless table regions.
Grouped headers
Nested headers and grouped columns can be preserved when merge geometry is trustworthy.
Extraction technology
How PDF table extraction works
The extractor reads text positions, table geometry, merged regions, and continuation patterns before writing cells into Excel.
Table boundary detection
Rows and columns are detected from PDF geometry and text placement.
Borderless fallback
When no grid lines exist, stable x-position anchors can recover table-like regions.
Grouped header handling
Parent-child header rows and horizontal header merges are preserved when reliable.
No OCR yet
Image-only PDFs are detected and rejected cleanly instead of producing garbage output.
Supported layout families
Built for real PDF table structures
TryPDF is designed around common table layouts seen in school, clinic, hospital, and office PDF reports.
Grouped headers
Parent and child header rows can be preserved when the PDF exposes reliable table geometry.
Landscape reports
Wide exports with many columns are handled without asking users to choose a special mode.
Merged cells
Trusted merged title, header, and section cells are kept while suspicious body merges are treated carefully.
Multi-page tables
Repeated continuation headers can be cleaned when they clearly duplicate the first table.
Common use cases
Useful for education, healthcare, and admin teams
These landing pages focus on practical PDF-to-Excel workflows instead of generic file-conversion claims.
Schools
Convert score tables, student lists, attendance sheets, and exam reports into editable Excel files.
Clinics
Review patient lists, lab result tables, and operational reports when the PDF is text-based.
Hospitals
Work with billing details, service tables, and multi-page healthcare admin exports.
Office teams
Turn landscape reports, grouped tables, and recurring admin PDFs into structured spreadsheets.
Supported examples
- Bordered report tables
- Clear borderless tables based on text alignment
- Grouped or nested header layouts
- Multi-page reports with repeated headers
Limitations to know
- Narrative paragraphs around tables may be ignored by design.
- Scanned PDFs need OCR, which is not enabled yet.
- Extremely irregular layouts may require manual cleanup in Excel.
Related workflows
Explore connected PDF-to-Excel use cases
Compare nearby conversion workflows when your document mixes invoices, statements, reports, or operational tables.
Extract tables from your PDF
Upload a text-based PDF and let the converter build an editable Excel workbook in the background.
Extract tables from a PDFFrequently asked questions
Is this just a PDF text copier?
No. It builds an .xlsx workbook from detected table rows, columns, and merge structure.
Can it extract borderless tables?
Yes, when the page has stable alignment patterns and enough repeated row structure.
Does it expose raw extraction warnings?
No. Public pages show simple review notes. Detailed telemetry is kept internal.